Case Study
Overview
Syncosaurus is a React-Javascript developer framework for rapidly building browser-based real-time, collaborative web applications backed by Cloudflare Workers and Durable Objects.
In this case study, we will:
- Define real-time collaborative applications
- Explain why real-time collaborative applications are not trivial to build
- Compare existing solutions used to facilitate building collaborative applications, including Syncosaurus
- Discuss how to use Syncosaurus
- Explain how Syncosaurus was built
- Discuss future improvements for Syncosaurus
Introduction
Defining Real-Time Collaboration Applications
Broadly, real-time collaboration is a term used to describe software or technologies that allow multiple users to work together on a project simultaneously. For our purposes, collaborative applications are browser-based web applications that enable multiple users to simultaneously edit and maintain a synchronized view of an artifact (e.g. a word document or an online whiteboard).
With the rise of remote work and distributed teams, apps like these are becoming critical in the modern work environment. Well-known examples include Google Docs, Figma, and Notion among others:

While a broader definition of real-time collaboration applications can include video conferencing and messaging software, those types of applications have different technical requirements and will be excluded from the scope of this case study.
Preface on Architecture
At a fundamental level when multiple users are “collaborating” on the same artifact, they are exchanging data to manipulate the synchronized view of the artifact. Practically, this means that all users who are collaborating on the artifact will need to exchange information back and forth in real-time via the open internet. Although there are numerous architectures for web applications, they can broadly be categorized into two categories:
- Centralized
- Decentralized
Centralized
Centralized includes the client-server architecture where client machines send resource requests to a backend server. In the client-server architecture, the server is generally authoritative, meaning it is the source of truth.
Decentralized
Decentralized such as the peer-to-peer architecture where every machine (known as a node) is treated equally and responsible for sending and responding to requests for resources. In the peer-to-peer architecture, every machine has equal authority and a consensus must usually be reached to determine the truth.
Though it is possible to build decentralized real-time collaboration web apps, decentralized architectures are notoriously complex. Instead many existing real-time collaborative apps use a form of the client-server architecture due to their comparative efficiency and ease of maintenance. Therefore, we will assume that any application considering Syncosaurus will be using a form of centralized architecture.
Building Real-Time Collaborative Applications Is Not Trivial
Initially, building real-time collaborative web apps may not seem different than building other web apps, however, if we break down each word of “real-time collaboration” into more concrete requirements, we quickly realize that is not the case.
What Does Real-time Entail?
Defining Real-time
Due to the laws of physics (e.g. the speed of light) and other causes of network latency, true real-time on the internet can never be achieved. Therefore, real-time communication benchmarks for the Internet are often described in milliseconds - response times of up to 100 milliseconds are usually categorized as real-time. The basis for this benchmark is a study that determined the average human requires 250 milliseconds to register and process a visual event.
Importance of Real-time
The need for real-time depends on the web application and generally apps that mirror in-person interaction or need rapid information sharing are strong candidates, including:
To illustrate this need and the impact latency can have on a user’s experience, drag the blue slider below and notice how higher latencies cause a noticeable delay in updating the green slider’s position to match:
Latency
Achieving Real-time Communication
At the application layer of the internet, HTTP underpins much of the communication, however, it is designed around a request-response cycle pattern which is not necessarily conducive to real-time latency standards given that a roundtrip from client to server is required for all communication. Therefore, since the type of real-time collaboration applications we are considering uses a client-server architecture, need bi-directional communication due to sub 100 ms latency requirements, and need high data integrity to ensure all users see the same view, only a few communication options (among several) merit our consideration:
- Long polling
- WebSockets
- WebTransport
Note that using streams over HTTP/2 was also considered due to its bi-directional nature and built-in multiplexing, however, the need to broadcast data to multiple clients in real-time collaborative apps (which we will discuss later) made them unsuitable for our purposes.
Long Polling
Long polling is a technique to emulate server push communications via normal HTTP requests.
Long polling works like this:
Although every browser supports long polling, it has high latency compared to other options such as WebSockets, and a risk of missing messages without extensive code on the client and server. Therefore, long polling is generally better suited as a fallback option as opposed to a primary means of bi-directional communication.
WebSockets
WebSockets is an application layer protocol that provides a full-duplex communication channel over a single, long-lived connection between the client and server. This means that similar to a phone call, the connection from the client to the server will stay open as long the network is not interrupted and neither the client nor the server actively terminates it. This open connection enables clients and servers to freely exchange data without the overhead of the HTTP request-response cycle, but because it is built on top of TCP, it still has guaranteed in-order message delivery.
WebSockets work like this:
Once the handshake is complete, the WebSocket connection is established and both parties are now free to transmit data at any time.
Websockets are low latency compared to HTTP and are widely supported in modern browsers, though they can be somewhat tricky to scale and maintain in production because the connections have to remain open and there is a risk of message loss when connections are interrupted.
WebTransport
WebTransport is an application layer protocol built on the QUIC protocol, a more performant alternative to TCP that still provides the benefits of guaranteed message delivery, with the performance of UDP. The WebTransport process works very similarly to WebSockets, however, the handshake process is quicker. Unlike WebSockets though, WebTransport provides multiplexing, which can decrease latency and reduce head-of-line blocking concerns.
While the characteristics of WebTransport make it seem like a strong fit for real-time collaborative web apps, the technology has yet to reach the same level of browser support as previously mentioned options.
Choosing a Technique
With real-time collaborative apps requiring a communication option with low latency, bi-directional messaging, wide browser support, and minimal data loss, many developers, including us, opt to use WebSockets. Though, as noted Websockets are not without their concerns, which will be discussed later in the case study.
Now that we have a more concrete definition of real-time communication latency requirements (< 100 milliseconds) and the communication options to enable that, we will seek to define collaboration.
What Does Collaboration Entail?
As mentioned previously, when multiple clients are “collaborating” on the same artifact, they are exchanging data to manipulate the synchronized view of the artifact. This synchronized view is known as the application state - the data or variables that determine the application’s appearance or behavior and which is often referred to as the “document” in collaborative applications.
To better illustrate the concepts of the current and subsequent sections in our case study, we will use a hypothetical example - a collaborative whiteboard application built using WebSockets.
Demonstrating Collaboration
In our example whiteboard application, all users expect to simultaneously see the same shapes (i.e. a consistent application state) so that they can react and respond accordingly:
If we assume the app is using a client-server architecture where the clients do not hold any state of their own (i.e. thin clients), the change-initiating client would need to wait until the change is received and confirmed by the server and then propagated to all clients before seeing the change reflected in its state.
Consistency vs Latency
One may assume that because our application is using WebSockets, the information would travel fast enough to meet real-time latency requirements. However, depending on where the backend server(s) is located (among other factors), the distance between the client and the server can increase latency. Unfortunately, this latency can create a laggy user experience for the change-initiating client while it waits to communicate with the server (note that this discussion alludes to the inverse relationship between state consistency and latency which is described by the PACELC theorem).
Using our whiteboard example, you can see that the users have a different experience when latency is introduced:
To increase consistency in our application, we will now explore tools and techniques to help us reduce latency.
Latency Reduction to Local Client-state
When striving to reduce latency in real-time applications for the change-initiating client, some potential approaches include:
- Using the edge network
- Tuning WebSocket messaging
- Updating the UI optimistically
The edge network is a distributed computing paradigm that brings computation and data storage as close as possible to the client. While using the edge network could be advantageous in reducing latency, it may involve overhauling the backend and could introduce complexity and consistency concerns of its own due to its distributed nature. Therefore, it may not be our initial choice.
Next, while tuning our WebSocket messaging to be more performant could also help in reducing latency, this strategy reaches diminishing returns because there will always be at least some latency in the network. Therefore, it will only get us so far.
Finally, optimistically updating the client’s UI (known as client-side prediction in the gaming world) takes a different approach - instead of seeking to reduce actual latency, it seeks to reduce perceived latency (i.e. how fast a website seems to the user), which as demonstrated in product design is often just as powerful. For our whiteboard application, this means the latency will still exist, but it will not be as apparent to the user.
Optimistic UI works like this:
An important implication of implementing optimistic UI is that each client has a local replica of the state that must be kept in sync with the server. Thus using it in our whiteboard app means that it now has distributed state. Figma uses this same technique - when a client opens a Figma design file, a copy of the document is sent from the server to the client and it must be kept in sync going forward:
However, as we’ll see in the next section, maintaining multiple copies of client state and a server state in the context of shared editing means conflicts can and will arise.
Inevitability of conflicts
Since the advent of Google Docs, the ability for multiple clients to simultaneously edit a document has become commonplace. However, simultaneous editing invariably leads to shared state conflicts because multiple clients can make changes to the same part of the state at the same time. Using our whiteboard app as a demonstration let’s say client A decides that they want to change the color of an existing blue shape to green, while client B decides they want to change the color of the same shape to red at the same time:
If these changes occur simultaneously, a conflict clearly occurs and to maintain a consistent, synchronized view across clients (i.e. state convergence), there must be some kind of conflict-resolution strategy in place.
Conflict Resolution Strategies
There are several well-known strategies for resolving conflicts in a distributed state, including:
- Transactional Conflict Resolution
- Conflict-free Replicated Data Types (CRDTs)
- Operational Transformation (OT)
However, before comparing strategies, it is worth reiterating that the initial decision to focus on apps using the client-server architecture affords the option to designate the server as the source of truth and the machine with the sole authority to resolve conflicts to ensure state convergence. Whereas with a peer-to-peer architecture, the only option to ensure state convergence is to use some kind of consensus algorithm, which can be complex and difficult to implement.
Transactional Conflict Resolution
Transactional conflict resolution, also known as Client-side Prediction and Server Reconciliation in video games, is a technique to resolve conflicts using the intent of each state change rather than the outcome of each change to ensure that state converges.
This means that if a change is intended to be applied relative to the current state (e.g. adding 1 to a count shared across multiple clients), multiple changes that could be considered conflicting would be stacked on top of each other instead. For example:
However, if a change is meant to be deterministic, meaning the same outcome is produced based on the same input (e.g. changing the color of shape), multiple changes to that property would result in the last one to arrive as the outcome:
The process of transactional conflict resolution is somewhat simple to reason about.
If two clients make a concurrent change to the same object but modify a different property, no conflicts occur. Because clients only send the intent of a change, these can both be processed in the order of arrival by the server.
When concurrent changes occur to the same property, a conflict occurs. By default, the server resolves this conflict using a simple Last Write Wins (LWW) approach. The server then broadcasts the resolved state to all clients.
However, depending on the application, it is possible to build in any custom conflict resolution that would override the default Last Write Wins Behavior.
While this strategy may not be best suited for use cases where LLW is not the desired default resolution strategy or for decentralized architectures, it is highly flexible and easy to reason about.
Conflict-Free Replicated Data Types (CRDTs)
A CRDT is a technique to solve conflicts using a complex data structure that relies on the mathematical properties of commutativeness (i.e. states can be merged in any order and the same result will be produced) to ensure that conflicts are resolved and states converge. There are CRDTs designed for different use cases, but broadly, there are two categories:
- State-based CRDTs which transmit their full state between peers, and a new state is obtained by merging all the states together
- Operation-based CRDTs which transmit only the actions that users take, which can be used to calculate a new state
We will use a simple operation-based CRDT example to demonstrate how they work in a broad sense:
Generally, although CRDTs can be used in server authority models, they are best suited for decentralized systems because they do not require an authoritative server. CRDTs are also a strong fit for applications with offline support because the data structure can preserve edits by an offline client and automatically merge them when the client regains connectivity.
However, CRDTs require a lot of computational and bandwidth overhead and are overkill for some use cases where they are applied.
Operation Transformation (OT)
OT is a technique to solve conflicts using a set of algorithms that compare concurrent operations and detect if the operations will allow the state to converge. If not, the operations are modified (or transformed) to resolve conflicts before being applied to the state:
Much like CRDTs, OT is known to be complex to reason about and can theoretically be implemented in a distributed fashion, however, it is overly complex so most OT implementations rely on a central server, which is still complex to implement itself.
Unlike CRDTs, however, OT is known to be less overhead.
Choosing a Strategy
As illustrated, no one-size-fits-all solution for conflict resolution exists because it depends on developer preference, application requirements, and the application’s architecture. However, because transactional conflict resolution meshes well with the client-server model, is the most flexible (it can even be used in tandem with CRDTs), and gives control back to the developer to resolve any conflict how they see fit, it is a natural fit for many real-time collaborative applications.
Real-time Collaboration in an Application
As demonstrated WebSockets and transactional conflict resolution are a strong fit for many real-time, collaborative applications. However, there are additional considerations if we were to build a production-ready collaborative application.
Rooms
Returning to our whiteboard example, once clients have sent a request to connect to the whiteboard, we’d need a way to maintain their WebSocket connection, handle incoming updates, and then broadcast those updates to each client's WebSocket connections. Multiple collaborative application framework providers (Reflect and Liveblocks) refer to this concept of a group of active WebSocket connections and a document as a “Room.” It is also the term Syncosaurus adopted in its terminology and we will be using it throughout the rest of this case study.
Client Routing
Let’s also assume we want to extend our application to allow a user to create multiple whiteboards and collaborate on each one with a unique set of other users. To achieve this, we’d need a routing mechanism to ensure clients are connected to the correct room and can initially load the correct document.
Document Storage
Finally, let’s assume we want to extend our whiteboard application to allow clients to collaborate on the same document across multiple sessions. To achieve this, we’d need a storage mechanism to enable the persistent storage and retrieval of documents upon room connection.
Solutions
Now that we understand some of the considerations of building real-time collaborative applications, let’s imagine we were to follow through with the implementation of our whiteboard application. Broadly, we’d have two options:
- DIY which means provisionining infrastructure and building everything from scratch and/or integrating existing tools
- Commercial which means using a comprehensive framework that addresses infrastructure, state syncing, and conflict resolution for real-time collaborative applications
DIY
From a simplified perspective, implementing a DIY solution will consist of the following steps:
- Deploy Infrastructure:
- Choose a cloud provider (e.g. AWS)
- Set up servers to maintain WebSocket connections
- Set up persistent storage for documents
- Set up routing for clients
- Write application code:
- Research and implement a conflict-resolution and state-syncing strategy (e.g. YJS could be used for CRDTs)
- Write backend logic to handle updates from clients, manage shared state via the chosen conflict-resolution strategy, persist state to storage, and broadcast updates to clients via WebSockets
- Write client logic to capture user events, make changes to the state, implement optimistic UI, and communicate with the server
As you can see, building from scratch is quite an undertaking, even if you take advantage of existing tools. However, this approach does offer greater control and customization over the entire system.
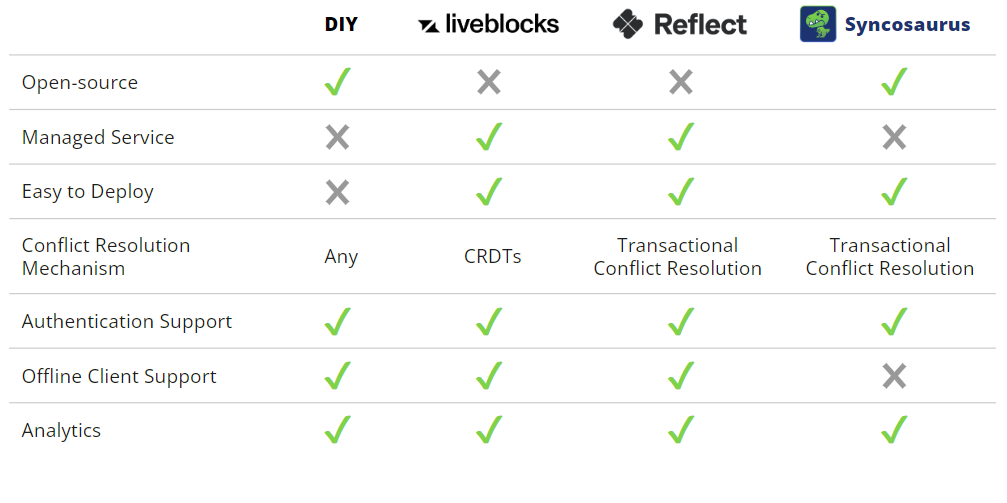
Commercial
Some of the most notable commercial solutions are Liveblocks and Reflect, which are primarily differentiated by the conflict resolution model each one employs. These commercial solutions offer convenience by abstracting much of the discussed complexity of a DIY solution by automatically deploying the infrastructure and handling the backend logic while exposing a client-side SDK to developers.
However, this convenience comes with a price - these solutions each use a monthly freemium pricing model. Liveblocks paid tiers start at $99 / month and Reflect paid tiers start at $30 / month as of the time of writing this. Additionally, using a commercial solution limits the amount of control and customization the developer has over the backend of their application.
Where Does Syncosaurus Fit In?
Syncosaurus is a React Javascript client-side SDK with full ready-to-be-deployed backend functionality. It is best suited for developers of small-to-medium-sized applications who want to rapidly develop and ship real-time, collaborative features in their applications.
Similar to commercial solutions like Liveblocks and Reflect, Syncosaurus exposes a client-side SDK while abstracting the backend logic and handling much of the deployment - the only thing a developer has to do to get the backend deployed is sign up for a Cloudflare account and use our CLI to deploy. However, unlike the commercial solutions, the Syncosaurus framework is free to use and open source so a developer can alter the default backend code if they choose.
Using Syncosaurus
To better understand Syncosaurus we will explore the syncing model and then walk through how a developer might use the tool.
Syncing Model
As mentioned, Syncosaurus uses a real-time syncing model with transactional conflict resolution to keep state consistent across multiple clients.
When a client makes a change to state, it is immediately applied to the client’s locally and the client places a copy of the intent of the change (i.e. a state mutation) in a pending queue.
Next, the mutation is sent across the WebSocket connection to the Syncosaurus server. Once the change is made to the authoritative state, the server sends a confirmation update to the client, which the client then uses to update its state to match the server and remove the pending state mutation from the queue.
When more than one client is connected to a given room, any mutations from one client are broadcast to all other clients by the server. Because an update from the server is authoritative, all client states are guaranteed to converge.
Development
Now that we understand the fundamental syncing model of Syncosaurus, we will discuss how to use the framework.
CLI Setup
The first step to use Syncosaurus is to install the CLI tool by running npm install -g syncosaurus-cli
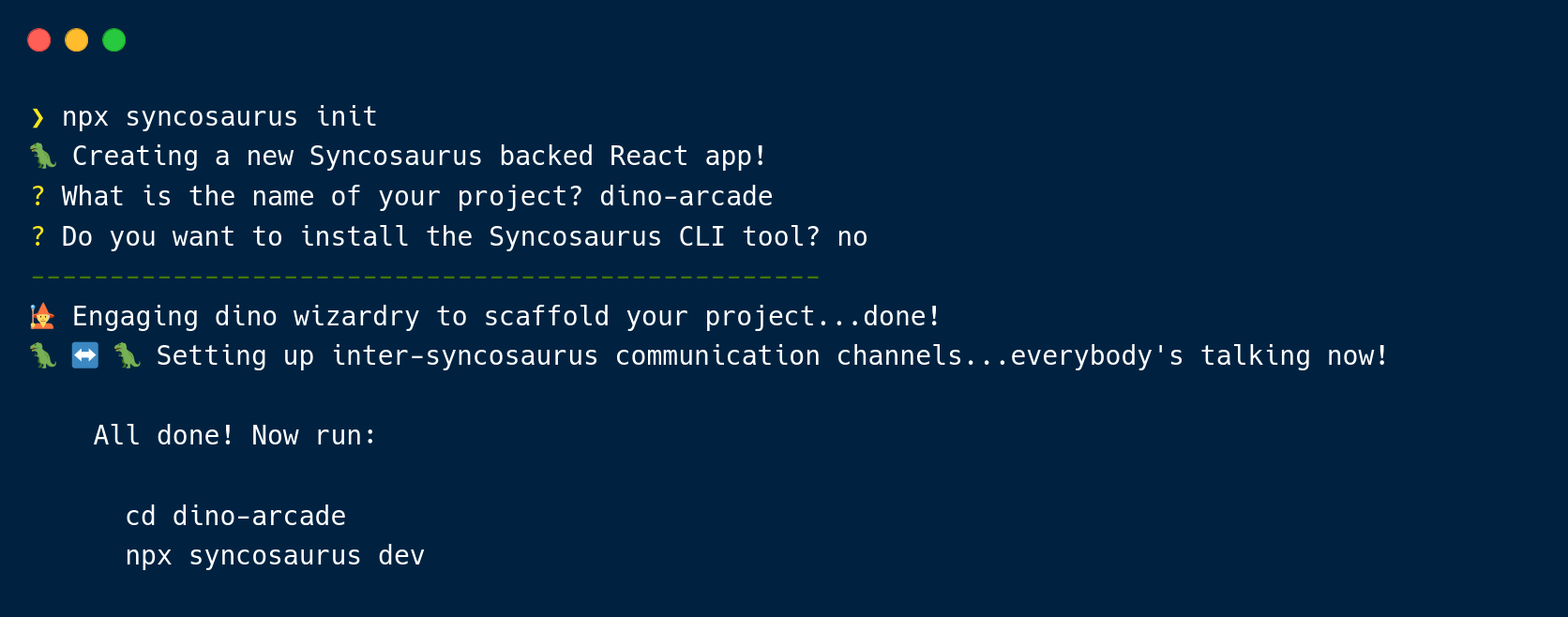
Next one can choose to add Syncosaurus to an existing React project using npx syncosaurus setup or create a project from scratch using npx syncosaurus init
Create and Launch
To use Syncosaurus in a React application’s code, one should import and initialize Syncosaurus:
const synco = new Syncosaurus({
mutators,
userID: user.id,
server: ws://localhost:8787 // The dev server runs on port 8787 by default
});
Next define the logic to create and/or join a room by passing in a RoomID to the launch method:
synco.launch(roomID);
Model Data Shape
Next, one should model the data shape that backs their application. Though the data shape of the key-value data store (i.e. document) is not strictly enforced, modeling it upfront allows a developer to better reason about their application logic
The shape for our to-do list could look like this in JavaScript:
{
'todo/1234': {
id: 1234,
text: 'walk the dog',
complete: true
},
'todo/1235': {
id: 1235,
text: 'take out the trash',
complete: false
}
}
Define Mutators
Next, we need to define the “write” logic for the application using mutators. Mutators are javascript developer-defined functions that contain the logic to update and manipulate the shared state based on user events in your application.
A mutator to add a new to-do to a list could look like this:
function addTodo(tx, { id, text }) {
const todo = { id, text, complete: false };
await tx.set(`todo/${id}`, todo);
return todo;
}
Define Subscriptions
Finally, to render the shared state on the client, we need to read the data from our local key-value store and determine how to display it using subscriptions. A subscription is implemented in the client code using a custom React hook called useSubscribe that reads data from the local store and re-renders components when updates to the value(s) for a specific key or set of keys (known as a watchlist) in the local storage occur.
A subscription to get all todos could look like this:
const todos = useSubscribe(
syncosaurus,
(tx) => {
let todoObject = tx.scan(key => {
return key.includes('todo');
});
return Object.values(todoObject);
},
[]
);
Putting It All Together
We have prepared a simple todo list application to illustrate the mutator and client code and the behavior we expect.
- mutators.js
- client.jsx
export default {
addTodo,
removeTodo,
}
function addTodo(tx, { id, text }) {
const todo = { id, text, complete: false }
tx.set(`todo/${id}`, todo)
return todo
}
function removeTodo(tx, { id }) {
tx.delete(`todo/${id}`)
}
import { useState } from 'react'
import Syncosaurus from 'syncosaurus'
import { useSubscribe } from 'syncosaurus'
import mutators from '../mutators.js'
const synco = new Syncosaurus({
mutators,
userID: '1234',
server: import.meta.env.VITE_DO_URL,
})
synco.launch('yourRoomID')
export default function App() {
const [inputValue, setInputValue] = useState('')
function handleChange(e) {
setInputValue(e.target.value)
}
function handleSubmit(e) {
e.preventDefault()
synco.mutate.addTodo({
id: uuidv4(),
text: inputValue,
})
setInputValue('')
}
function handleDelete(id) {
synco.mutate.removeTodo({ id })
}
const todos = useSubscribe(
synco,
tx => {
let todoObject = tx.scan(key => {
return key.includes('todo')
})
return Object.values(todoObject)
},
[]
)
return (
<div>
<form>
<input type="text" value={inputValue} onChange={handleChange} />
<button onClick={handleSubmit}>Add Todo</button>
</form>
<ul>
{todos.map(todo => (
<li key={todo.id}>
{todo.text}
<button onClick={() => handleDelete(todo.id)}>Delete</button>
</li>
))}
</ul>
</div>
)
}
Go ahead and enter some todos into Client 1 and watch them appear on Client 2 after a simulated latency of 1 second:
Todo List (Client 1)
Todo List (Client 2)
Deployment
After you’re satisfied with the local version of the application, it can be deployed to Cloudflare by running npx syncosaurus deploy. Once the CLI completes deploying, simply update the server URL provided to your Syncosaurus object at instantiation. Note the switch from the ws to the wss scheme.
const synco = new Syncosaurus({
mutators,
userID,
server: 'wss://[PROJECT_NAME].[ACCOUNT_NAME].workers.dev',
});
Monitoring
After your application is deployed, you can monitor its usage and get help debugging via the analytics dashboard and a live tail log.
The dashboard includes hourly time-series metrics related to errors and usage for each room so you can verify users are able to access and use your application in a bug-free manner.
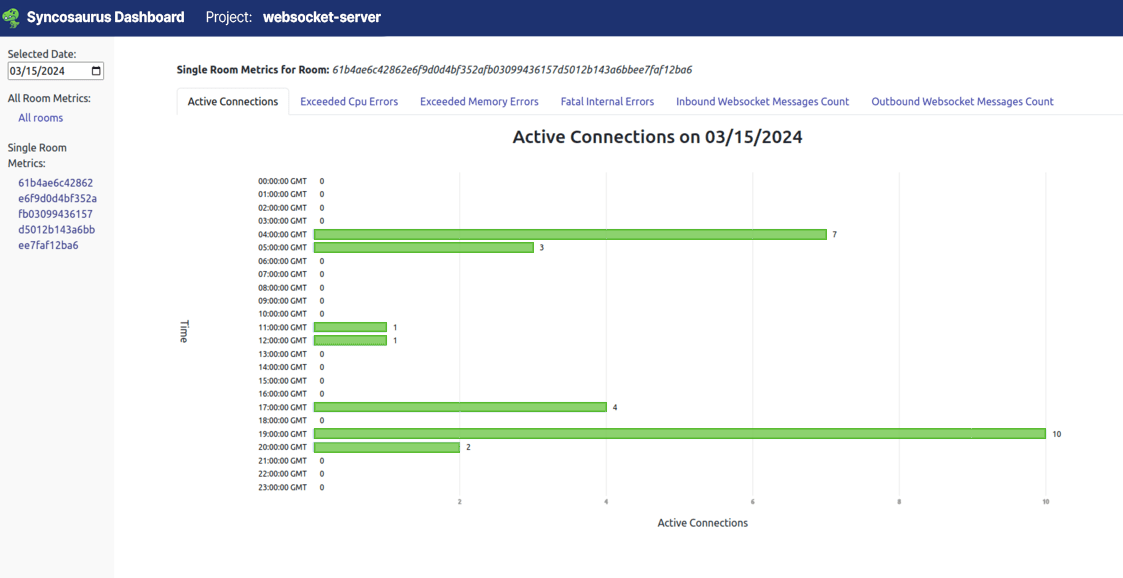
For even more detail, a tail logging session for your deployed backend can be started by running npx syncosaurus tail
Building Syncosaurus
Now that we understand Syncosaurus at a high level, we will discuss how we built it, starting with a brief recap on requirements, then a discussion on architecture, followed by a discussion on decisions and tradeoffs made while building Syncosaurus.
Requirements
Before we can discuss the architecture of Syncosaurus, it’s important to summarize the requirements we’ve mentioned so far. Since we are building Syncosaurus to support production-ready applications, at a minimum it should support:
- The syncing model with transactional conflict resolution
- Multiple concurrent rooms (maintaining WebSocket connections and broadcasting messages)
- Persistent storage of documents
Architecture
Server vs Serverless
There are many different models of cloud computing ranging from infrastructure-as-a-service to serverless and each one offers varying degrees of infrastructure upkeep and flexibility. While server-based models (e.g. virtual private servers) offer greater control over the infrastructure, when choosing a model for Syncosaurus we quickly narrowed in on a serverless model (i.e. functions-as-a-service) due to its alignment with our use case of supporting the rapid development and release of real-time features in small-to-medium sized applications, including:
- Less overhead because there is no need to manage and maintain servers
- Granular scalability which creates potential cost savings as there are fewer wasted resources compared to a server-based model where you have to pay for the server even if it is not being used
- High availability which can reduce response times and aid in meeting real-time latency requirements
Although, serverless is not without its tradeoffs including cold start issues and challenges around testing and debugging.
Traditional Cloud vs Edge
Several serverless model cloud providers offer both traditional and edge-based options (e.g. AWS Lambda vs AWS Lambda@Edge). Traditional cloud computing connotes remote servers in managed data centers that are not necessarily close to their clients which can increase latency. Whereas edge computing means servers and data storage are positioned “as close as possible” to the source of data with the intent of reducing latency.
For Syncosarus, we ultimately elected to deploy on the edge and accept tradeoffs around added complexity and reduced robustness since reducing latency in real-time applications is paramount.
Cloudflare Workers and Durable Objects
When choosing a provider to build on, we narrowed in on a couple of options.
First, we could have built our serverless edge infrastructure using a combination of AWS Lambda@Edge, Amazon API Gateway, and a persistent storage mechanism like AWS Dynamo DB:
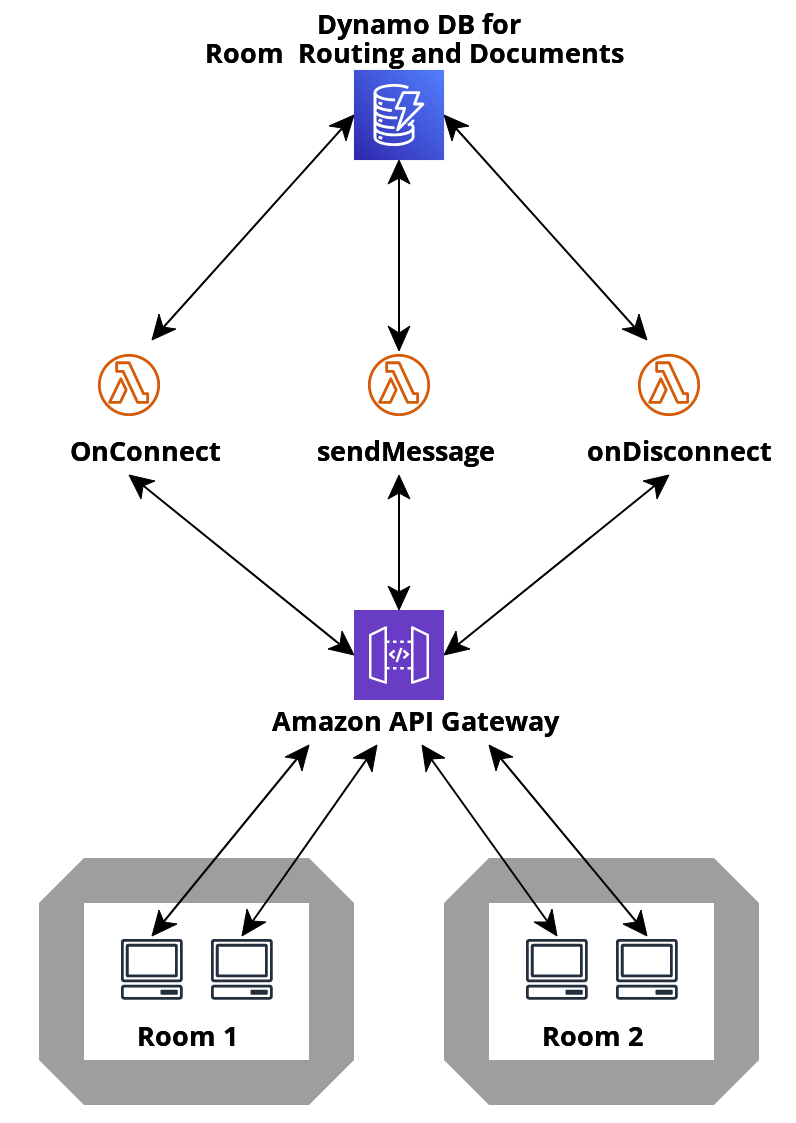
While this is a valid approach, it does involve provisioning and connecting several components which can increase the complexity of deployment and maintenance.
As previously mentioned, we instead ended up choosing a Cloudflare-based architecture consisting of Workers and Durable Objects due to its simplicity and extremely strong fit for our use case.
A Worker is an edge-based serverless function on the Cloudflare network. A Durable Object (DO) is a special type of Worker - a globally unique JavaScript isolate (a unique JS engine) with access to its own private strongly consistent storage and built-in caching.
DOs provide a single point of coordination for WebSockets and have built-in document persistence allowing us to make the workers stateful without the use of a remote persistent storage mechanism like Dynamo DB in the above AWS solution, which can lead to increased latency. It is important to note that a DO (including its persistent storage) can be geographically migrated based on client location, which limits the latency negation of requests accessing storage, an important factor when deciding between cloud vs edge
However, it should also be noted that DOs have limitations, most notably that the persistent storage only supports key-value pairs and that a DO has a soft limit of 1,000 requests per second. This means that depending on the volume of requests a single client sends and the number of concurrent WebSocket connections, a DO could run into scaling issues.
As we’ve defined, real-time collaborative applications should emulate at most a board meeting (~15 WebSocket connections), not a town hall (~100 WebSocket connections), therefore scaling concerns around the number of concurrent WebSocket connections and the number of requests per second were minor with optimizations put in place as we’ll discuss shortly.
Engineering Challenges
When engineering Syncosuaurus, we had to be thoughtful about the efficiency of the syncing system and ensure that a developer using the framework would have a pleasant experience. In this section, we will discuss some of the considerations that went into those engineering decisions.
Challenge: Authoritative Update Size
A naive implementation of authoritative updates sent from the server to clients would be to broadcast the entire state from the server to all clients when each change occurs.
However, an issue with this approach is that as the document grows in size, the message size containing the authoritative state sent from the server to the client will grow equivalently. This has two consequences:
- Larger update sizes mean that the WebSocket messages will take longer to transmit
- Once a message arrives at the client, it will take longer to process and update its entire local state
An alternative approach to prevent this is to send an update that only contains the changes that the server, also known as a delta update approach:
We ultimately decided on the delta update approach for the efficiency gains, however, this decision introduced the risk that a missed update by a client could lead to a divergent state.
Challenge: Missed Authoritative Updates
As mentioned, a risk of using delta updates is the heightened potential for missed messages and divergent state. This is because when a WebSocket connection temporarily drops and reconnects, missed updates can occur in the interim. Therefore, we needed to implement a connection state recovery mechanism that would bring the client back up to date in this scenario.
To do so, we implemented an incrementing batchID which is sent by the DO as a property on every update message broadcasted to the clients. Each client tracks the batchID of the last message it received from the DO and when it receives a new message, it compares the previous batchID against the new one to determine if it missed an update. If a client misses an update, it sends a special request to the DO for a copy of the entire latest state.
Note that sending only the delta updates missed could reduce the state recovery message size and latency, however, the DO currently does not keep a log of the updates it broadcasts. This is an area for future investigation since it would likely create greater memory and storage demands on the DO.
Challenge: Authoritative Update Frequency
Another area of consideration was the trigger mechanism of authoritative updates sent by the DO. Generally, we considered two approaches:
- Event-driven model
- Time-driven model
Event-driven model
Using an event-driven model means that for every message sent by a single client to the DO, M update messages are broadcasted by the DO, where M represents the number of connected clients. While this approach requires simple logic, in production, it can quickly present a scaling concern.
If we assume all clients are sending messages simultaneously and we are targeting a certain message per second rate (i.e. frame rate per second (FPS)) broadcasting would scale at a rate of O(M^2*N) where N represents the number of messages sent per second by a single client.
In testing done by Reflect, the target budget of a DO should be approximately 2,000 calls per second to WebSocket.send (a call to transmit a message over a WebSocket connection). This means, that if an app wants to target 60 FPS (a standard in gaming) it can only have 6 concurrent users (60 messages/second = 2000 calls / (6 users^2)). While a 6-user limit is suitable for some applications, it does shrink the pool of applications Syncosaurus could support.
Time-driven model
A time-driven model means that the DO would group state changes into a single update and send out a periodic message based on a configurable time frequency.
This frequency directly correlates with the frame rate and makes the messaging system scale at a rate of O(M*N). Therefore, if an app wanted to target 60 FPS (approximately every 16ms), it can support up to 33 concurrent connections.
The tradeoff with this approach is that a message will be sent whether an update has occurred or not, meaning there may be unnecessary empty messages sent. However, we decided this tradeoff was worth it to make our messaging more efficient (message scales at a rate of O(M*N) instead of O(M^2 * N)) and to expand the pool of Syncosaurus-compatible applications.
Challenge: Re-rendering and Subscriptions
An additional consideration was reducing unnecessary client-side rendering in React and making our subscription system robust. A naive implementation of subscriptions would re-rendered the entire UI every time an update from the server was received. However, this could lead to performance bottlenecks and does not take advantage of React’s model to re-render modular components individually when an update to the state they are concerned with occurs.
To make subscriptions fit React’s granular rendering model, we decided to allow developers to write query functions on per component basis that indicate which keys in the local store they want to watch for updates (known as a key “watchlist”). Furthermore, by allowing subscriptions to accept a query callback, the developer can transform data in this callback before returning the value to React to be rendered. Finally, an additional mechanism we put in place to reduce unnecessary re-renders was a check to ensure the result of the query had changed since its last rerender (i.e. memoization), otherwise a new render would not be initiated.
Though, there may be additional memory overhead with memoizing query results and maintaining a key watchlist, eliminating unnecessary UI re-renders and making subscriptions more robust leads to a snappier UI and gives developers more control over the rendering of their application, respectively.
Challenge: Ease of use
The last area of consideration was how to make Syncosaurus easier to use by other developers. After researching several solutions in the space and putting ourselves in a developer’s shoes, we decided to implement a couple of additional features:
- Optional authentication support for room access using JWTs
- An Analytics Dashboard to monitor and debug rooms
Authentication
The Syncosaurus framework supports token-based authentication that allows a developer to enforce proper room access if they choose. JWTs are commonly utilized for this, but other types of token-based authentication like OAuth can be used as well. To implement authentication, a developer must provide two components to work with our authentication handler:
- A token(s) or preferably a library or service that can generate new tokens
- An authentication service that verifies the validity of tokens
Analytics Dashboard
As demonstrated, Syncosaurus includes an analytics tool to easily view and analyze aggregate and single-room metrics for an application. The dashboard allows a developer to gain insights into usage and debug their application if necessary. The architecture for the analytics dashboard displays data from Cloudflare’s endpoints and visualizes it in a locally running front-end application that pulls from a custom-built GraphQL backend:
Future of Syncosaurus
And that's Sycosaurus! While it fully supports real-time collaborative applications like the puzzle shown on our landing page and beyond, there is still much room for improvement and feature parity with existing solutions. A few areas we plan to investigate next are:
- Offline mode support
- Undo/redo support
- More robust web socket connection handling
- More syncing model efficiency improvements
For more information regarding how to use Syncosaurus please see our documentation